KaggleのHungry Geeseコンペで、4位でした。この記事では、その解法を書きます。
Hungry Geeseコンペ4位でした!楽しいコンペでした。対戦ありがとうございました!! pic.twitter.com/EZS9EqAAFz
— カレーちゃん🍮kaggleのチュートリアル第5版公開中 (@currypurin) 2021年8月9日
このコンペの概要については、別記事の「Hungry Geeseコンペの概要」で書いていますので、そちらを参照。
強化学習
HandyRLというライブラリを使用して、このコンペに参加していました。
私が、コンペに参加した時3月の時点には、レーティング1000ぐらいのAgentが公開されており、そのAgentを流用しつつ、強くするように工夫するようにしました。
強化学習の利用を広めるべくkaggleで開催中のHungyGeese(蛇ゲーム)で、並列強化学習ライブラリHandyRLを用いた学習済みモデルとコードを公開しました w/ @cute_na_piglets
— Ikki Tanaka(kyazuki) (@ikki407) 2021年2月10日
ノートブックに乗る小さなモデル(<1MB)で1日で金圏に行けます(公開時点)
強化学習で勝ちましょう!https://t.co/6ZhY0ag64u
公開されていたHandyRLのAgentの概要は次のとおり。
- 入力は17チャンネル x 高さ7 x 横11
- 17チャンネルの内訳
- 頭の位置: 4チャンネル
- 頭がある位置を1にして、残りを0にする。(以下同じ)
- しっぽの位置: 4チャンネル
- 体全体の位置: 4チャンネル
- 1step前の体の位置: 4チャンネル
- foodの位置: 1チャンネル
- 頭の位置: 4チャンネル
- この入力をCNNに入れて、policy(東西南北)とvalueの出力
- 強化学習の仕方については、HandyRLチームの、以前のコンペでのsolution参照。
特徴量エンジニアリング
自チームが4位になれたのは、入力するチャンネルを工夫した要因がかなりを占めると思います。
上記の17チャンネルに加えて、次のようなチャンネルを加えました。
- 体の順番がわかる盤面: 4チャンネル
- 体全体を尻尾から順に、1.0, 0.95, 0.9, 0.85, ...というように0.05ずつ減らした盤面
- ターンが進むと、体のどこからなくなっていくかを表したかったので作成
- 次に体が確実になくなる or 体がなくなる可能性を表現した盤面:4チャンネル
- しっぽ及びしっぽの1つ手前の箇所のうち、次のターンに確実になくなる箇所は1.0、なくなるか・なくならないかわからない箇所は0.5。
- foodを食べる可能性と、40stepが経過して体が1つ短くなることを考慮しています。
- このチャンネルを入れたことで、次のことが可能となっています
- 相手の尻尾のマスに進んだ時に、相手がfoodを食べて尻尾がなくならずに、ぶつかってしまうのを防ぐ
- 40step毎に体が1つ短くなるタイミングで、相手の尻尾の1つ手前に進むことができる
- Agentの頭の位置と、自Agentとの差を表した盤面:1チャンネル
- 自分の体の長さと、相手の体の長さの差をとって、相手の頭の位置にその差を入力する盤面
- 自分の方が長い場合は強気に立ち回って欲しい、自分の方が短い場合は安全に立ち回って欲しいということをイメージして作成
学習方法
学習は、HandyRLの初期パラメータをほぼ使っていました。
- evaluation(評価)のAgentには、HandyRLが共有してくれたweightから追加学習したAgent(コンペ終了時点でレーティング1090ぐらい)を設定
- 学習曲線は次のもの(1epoch毎に200の新しいreplayを作成)
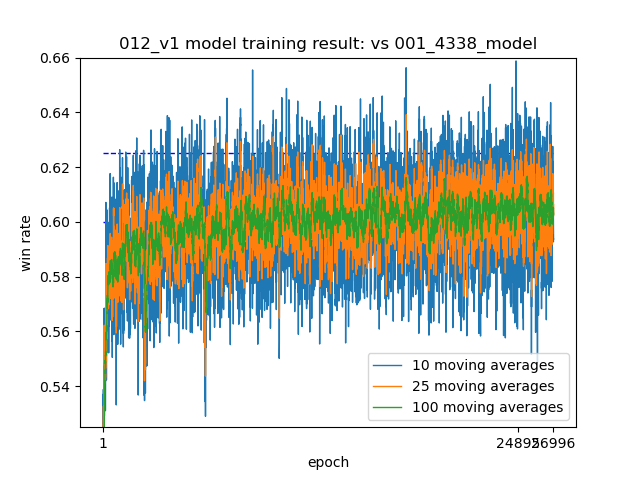
- 自チームの1番スコアの良いAgentは、この学習曲線の25,422epochのもの
- 自Agentと、レーティング1090ぐらいのAgent3体の対戦で0.61程度のoutcomeが平均して出るぐらいまで学習できているという学習曲線です。
- 1位→1.0, 2位→2/3, 3位→ 1/3, 4位→0.0のoutcomeなので、平均順位は2.1位程度
- ちなみにこのagentはコンペ終了まで1.5ヶ月ぐらいある時に作成してsubしたAgent。その後、ネットワークを変えてoutcomeの平均0.625ぐらいまで出ているけれど、おそらく過学習というやつで、LBは更新せず。
推論(TTA)
推論時に、盤面のaugmentationを行い、それを単純平均してargmaxをとる方法で進む方法を決めていました。
- augmentationは、Horizontal Flip、Vertical Flip、Horizontal Flip + Vertical Flip、augmentationなしの4つの盤面でそれぞれ予測
- このaugmentationをすることにより、LBのスコアが30ぐらい良くなる
- さらに、randomにnとmを決めて、盤面を左右にnマス、上下にm動かして上記のaug実施
- これを時間制限ギリギリの0.8秒ぐらい行い、単純平均しargmaxをとって進む方向を決定
- 0.8秒だと、平均で10回ぐらい位置を動かしてaugmentationでき予測値は40ぐらいできることになる
- LBのスコアの上積みはおそらく40ぐらいなので、回数を増やしてもそれほど強くはならない
学習時のテクニック的なやつ
- 一旦GPUとCPUを5日ぐらい回し続けてある程度強いAgentを作っています
- 強化学習の学習を0から学習するとものすごく学習に時間がかかる
- その後、headを削除し、そこまでのweightを固定して、後ろにネットワークを追加して、追加した箇所のweightのみを学習
- これにより、数時間から1日程度の学習でも強いAgentができますし、入力する特徴やネットワークの形などを変えて数多くの実験をすることができる
うまくいかなかったこと
- モンテカルロ木探索などの探索は、(主にチームメートが)取り組むも、スコアを改善せず。なので自チームの上位のsolutionは探索なし
- 学習データのaugmentationに取り組むも学習がうまくいかず
- 即時報酬の設定や、outcomeを修正して、foodを食べるよりも生存を目指すAgentを作ろうとするもうまくいかず
- 4人対戦専用Agent、3人対戦専用Agent、2人対戦専用Agentと、局面に応じたAgentを作ろうしたがうまくいかず
- 手元のvalidation(自分のAgentとの4,000試合程の対戦)では、それぞれ強く見えていたんだけれど、サブミットしてみるとスコアがあがらず
とりあえずsolutionとしてはこんなところです。
実際にどのように試行錯誤したのかなどは、別記事で書きたいと思います。質問があればtwitterやマシュマロなどでください。
コンペの感想
強化学習を始めて学びましたが、HandyRLという神ライブラリ、つくりながら学ぶ!深層強化学習 PyTorchによる実践プログラミングというとてもわかりやすい入門書のおかげですんなりと強化学習に取り組むことができ、金メダルを獲得することができました。
このあたりも別記事で書きたいと思います。
Youtube
Youtebeでも、solutionについて話しましたので、よろしければ見てください。