3月2日に開催された、分析コンペ 勉強会で、「Colaboratoryで分析コンペをする時のテクニック集」として発表をしました。
この記事では、その内容を書きたいと思います。
- Colaboratoryテクニック9つ
- 1. テーマの設定(darkモード等)、エディタの設定(インデント幅等)
- 2. ColaboratoryかKaggleNotebookか判別
- 3. Notebook名を取得
- 4.Google Driveのファイルへのアクセスを許可
- 5.学習する際は、MyDriveはなるべく使わない
- 6.a Kaggle Apiを使用する
- 6.b データのKaggleDatasetsへのアップロード
- 7 Mydriveからのweightのロードが遅い場合
- 8 Githubのrepositoryをclone
- 9. GitHubのプライベートリポジトリのipynbファイル開く、Colaboratoryで編集したのをGithubに保存する
- Colabolatoryを使うモチベーション
- 終わりに
- 追記(Colaboratory Proについて)
Colaboratoryテクニック9つ
ここでは9つの小ネタを紹介します。
1. テーマの設定(darkモード等)、エディタの設定(インデント幅等)
Colaboratory上部の「ツール > 設定」では、次の画像のように、テーマ、デスクトップ通知の表示の有無、フォント、インデント幅などを設定可能です。
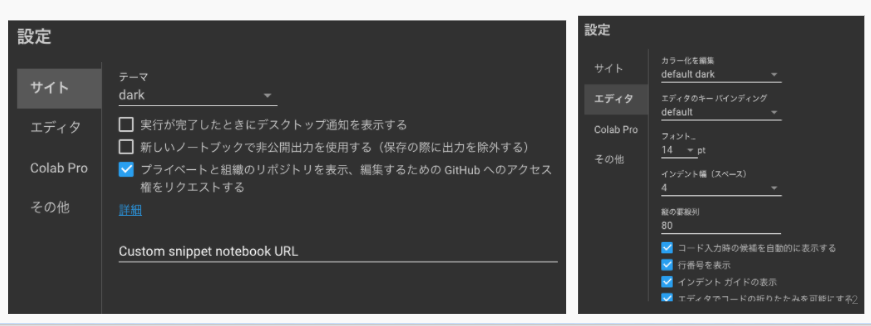
テーマは、light、dark、adaptiveから選択でき、darkでは文字の色も選択できます。

2. ColaboratoryかKaggleNotebookか判別
実行しているのがColaboratoryかKaggleなのか判別するコードです。
import sys # Colaboratory環境ならTrue 'google.colab' in sys.modules # Kaggle Notebook環境ならTrue 'kaggle_web_client' in sys.modules
例えば、INPUTの位置を動的に変えるようにして、ColaboratoryでもKaggleでも動くコードにすることができます。
import sys from pathlib import Path if 'google.colab' in sys.modules: # colab環境 INPUT = Path(‘/content/input/’) elif 'kaggle_web_client' in sys.modules: # kaggle環境 INPUT = Path(‘../input/’)
3. Notebook名を取得
Notebookのタイトルを取得するコードです。
from requests import get name_notebook = get('http://172.28.0.2:9000/api/sessions').json()[0]['name']
Notebook名を利用して、DriveにそのNotebook名のフォルダを作成し、学習した重みを保存するようにしています。
Notebook名の変更は、新しくNoteを作成した際にすることにすれば忘れないので、学習した重みの上書きを防ぐことができます。
4.Google Driveのファイルへのアクセスを許可
Google Driveのマウントの仕方です。
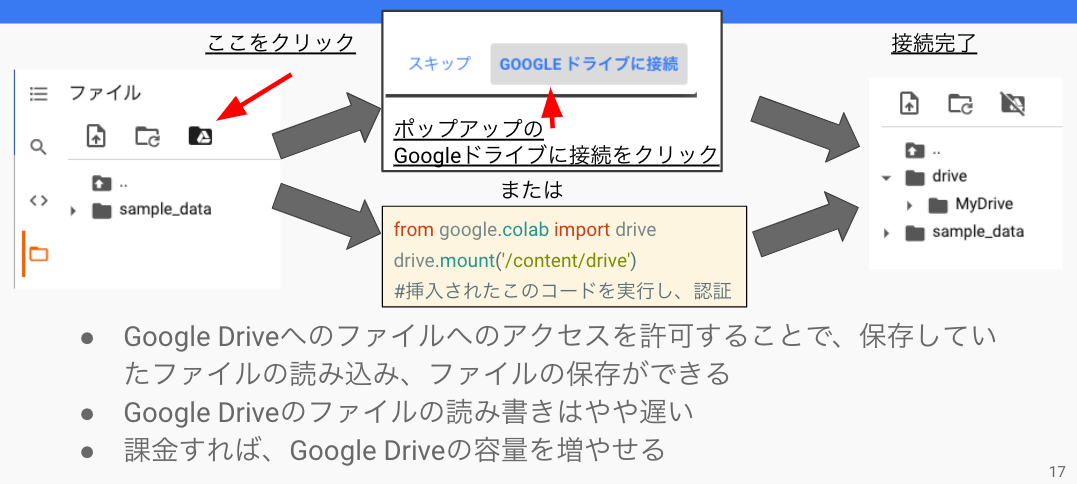
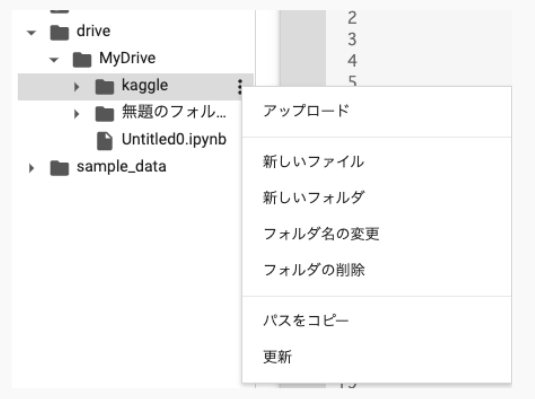
左にあるディレクトリの右端をクリックすることで、パスを取得することができます。 次の画像のkaggleフォルダであれば、‘/content/drive/MyDrive/kaggle’、sample_dataフォルダであれば、‘/content/sample_data’です。
5.学習する際は、MyDriveはなるべく使わない
MyDriveのファイルの読み書きは遅いので、なるべくcontent直下にファイルを移動して読み込んだ方が良いという小ネタです。
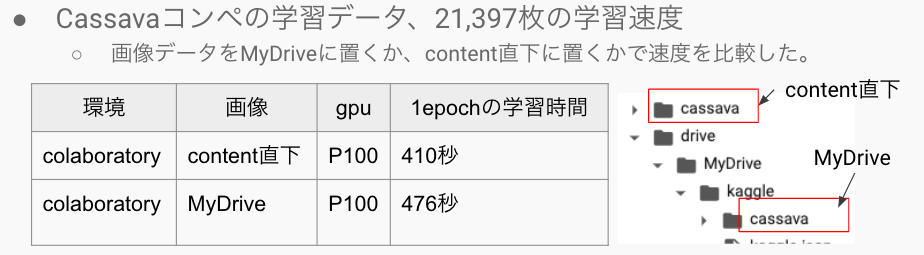
上の画像のように、今回の学習条件だと、MyDriveの方が1epochあたり、1分ほど遅い。
なので、MyDriveからcontent直下にコピーしてから学習した方が良いことが多いと思います。
6.a Kaggle Apiを使用する
次の画像のように、データがKaggleのデータの場合は、MyDriveからのコピーよりも、Kaggle apiでデータをダウンロードした方がやや速いです。

Kaggle apiを使用するためには、'root/.kaggle'にkaggle.jsonを置く必要があります。

6.b データのKaggleDatasetsへのアップロード
学習が終わった後、重みは自動的にKaggle Datasetsにアップロードするようにすると良いと思います。
Kaggle Datasetsを新規に作る場合は次のコード。
import json from kaggle.api.kaggle_api_extended import KaggleApi ID = ‘<自分のkaggleのID>’ DATASET_ID = ‘<datasetのid>’ UPLOAD_DIR = ‘<colaboratoryでのフォルダのパス>’ def dataset_create_new(): dataset_metadata = {} dataset_metadata['id'] = f'{ID}/{DATASET_ID}' dataset_metadata['licenses'] = [{'name': 'CC0-1.0'}] dataset_metadata['title'] = DATASET_ID with open(UPLOAD_DIR / 'dataset-metadata.json', 'w') as f: json.dump(dataset_metadata, f, indent=4) api = KaggleApi() api.authenticate() api.dataset_create_new(folder=UPLOAD_DIR, convert_to_csv=False, dir_mode='tar')
Kaggle データセットを更新する場合は、次のコード。
import json from kaggle.api.kaggle_api_extended import KaggleApi UPLOAD_DIR = ‘<colaboratoryでのフォルダのパス>’ VERSION_NOTES = ‘<version notes(前の版からの変更点)>’ def dataset_create_version(): api = KaggleApi() api.authenticate() api.dataset_create_version(folder=UPLOAD_DIR, version_notes=VERSION_NOTES, convert_to_csv=False, dir_mode='tar')
7 Mydriveからのweightのロードが遅い場合
たまにDriveからGPUへのweightのロードは遅い場合があったので、その場合はcontent直下にweightのファイルをコピーしてから読み込むと良いという小ネタです。
ただ、次の画像のように、昨日実験した際はロード時間に差がなかったので、気にする必要はないかもしれません。

8 Githubのrepositoryをclone
次の公式のページに詳しく書いてあるので、参考にするのが良いと思います。 Data_into_Google_Collab_guide.ipynb - Colaboratory
以下は、その抜粋です。
public repositoryをcloneする場合
!git clone https://github.com/username/repository.git /content/foldername
private repositoryをcloneする場合
password method という方法。ただし、推奨されないようです。
!git clone https://username:password@github.com/username/repository.git
SSH keyを使う次の方法を使いましょう。
!ssh-keygen -t rsa -b 4096 -C "username@github.com" !cat /root/.ssh/id_rsa.pub # これで表示されたkeyを、githubのsettings>deploy keysに登録 !ssh-keyscan github.com >> /root/.ssh/known_hosts !chmod 644 /root/.ssh/known_hosts !chmod 600 /root/.ssh/id_rsa !ssh -T git@github.com !git clone git@github.com:username/privaterepo.git /content/foldername
/root/.ssh/はセッションが切れるとなくなってしまうため、ローカルに保存したり、Driveに保存するなどして、毎回アップロードやコピーして使うと良いと思います。
9. GitHubのプライベートリポジトリのipynbファイル開く、Colaboratoryで編集したのをGithubに保存する
Colaboratoryの ファイル > Notebookを開く > Githubに進んで認証し、未公開リポジトリも含めるにチェックすると、githubのプライベートリポジトリのipynbファイルを開くことができます。
また、編集後、ファイルのGithubにコピーを保存で、Githubに保存することができます。
Colabolatoryを使うモチベーション
以上がColabolatoryを使う小ネタですが、以下Kaggleをするに当たってColaboratoryを何故使っているかという説明です。
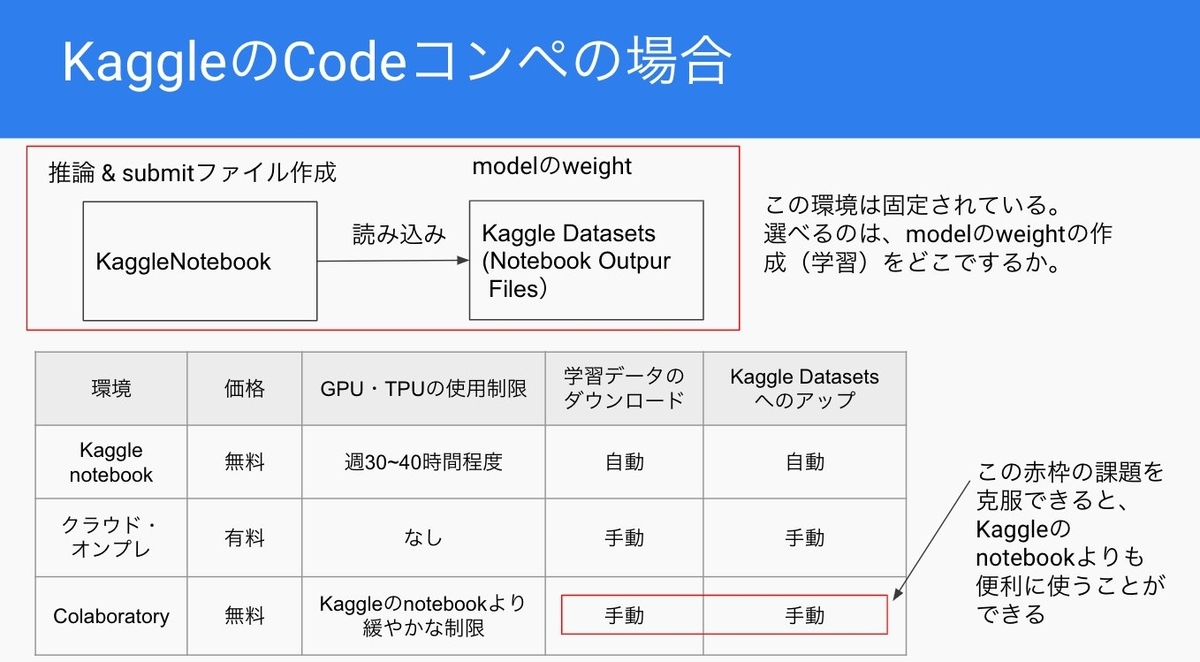
Kaggleのnotebookは無料で使えたり、学習データや学習したweightの使用がとても簡単にできます。
でもGPU・TPUは週30~40時間程度の制限があり、もう少しGPUを使いたいとなります。
クラウドやオンプレを使う方法もあるわけですが、有料なのでできたら無料で使える環境が欲しい。
そこでColaboratoryであれば、GPUやTPUが無料で使えるので、嬉しいです。ただ上の画像の赤枠のように、学習データのダウンロードやKaggle Datasetsのアップロードは手動で行う必要がありやや面倒です。
ここをKaggleのコンペの参加などを通してスムーズにできるようになったので、この記事にしています。
Colaboratoryとは
Colaboratoryは公式ページでは次のように説明されています。
Colaboratory(略称: Colab)は、ブラウザから Python を記述、実行できるサービスです。次の特長を備えています。
- 環境構築が不要
- GPU への無料アクセス
- 簡単に共有 「Colaboratoryとは」より
ただし、Colaboratoryはインタラクティブな使用を目的としており、長時間の学習には向いていないようです。
また、1セッション最大12時間の制限や、アイドル時間が長いと接続が切れることがあり、使い続けるためのいくつかのテクニック*1があります。
もう少しColaboratoryを使う人のために、Colab Proという有料版のサービスがあり、これは現在米国とカナダでのみ提供されています。3月中旬にColab Proが提供される地域が増えるとの噂があり、日本でも使えるようになることを期待しています。
Colab Proは公式ページでは次の画像のように説明がされています。

終わりに
上記の小ネタにはtwitterで教えてもらったネタがいくつもあります。それをcolaboratoryでkaggleをするときに便利なコード で書き溜め、勉強会での発表にし、ブログの記事にしました。
参考にしたページ
- 公式
- その他
- その他2
- Google Colaboratoryを便利に使うためのTIPSまとめ
- 本記事では分析コンペでの便利な使い方を説明しましたが、一般に便利使うTIPSとして、この記事が参考になります。
- Google Colaboratoryを便利に使うためのTIPSまとめ
追記(Colaboratory Proについて)
2019年3月19日、ついに日本でもColaboratory Proに申し込めるようになりました。
colab proついに来ましたか! https://t.co/XOZAfPhirQ
— カレーちゃん🍮kaggleのチュートリアル第5版公開中 (@currypurin) 2021年3月19日
通常のColaboratoryとProの違いは、現状このような状況。
colaboratory pro申し込んでみた。通常版からの変更点はこんな感じでしょうか。 pic.twitter.com/fzFVgJHvJ4
— カレーちゃん🍮kaggleのチュートリアル第5版公開中 (@currypurin) 2021年3月22日
比較のため、V100で回してみましたが、次のツイートの画像のようにとても早かったです。
Colaboratory V100引けたので、P100との比較で回してみた
— カレーちゃん🍮kaggleのチュートリアル第5版公開中 (@currypurin) 2021年3月23日
・V100はP100のおよそ半分の時間で学習が終わる。
・GCPの方がはやい。
一応条件は揃えたけれど、それぞれ2epoch回しただけなので、参考程度としてもらえれば。 pic.twitter.com/9kPQv7x2fN